
Projekt Sora od spoločnosti OpenAI ukázal, že generatívna umelá inteligencia dokáže na základe jednoduchého textového zadania vygenerovať pomerne realistickú filmovú scénu. Jedným z prvých výtvorov tohto systému bolo aj ázijské dievča prechádzajúce sa po meste, ktoré sa tak stalo symbolom tejto generatívnej AI.
Teraz tento produkt umelej inteligencie vzali odborníci z Inštitútu pre inteligentné IT, ktorý prevádzkuje Alibaba Group, a naučili ju „rozprávať a spievať“. Sora, ako dievča prezývame, ale nebola jediná, na ktorej si vyskúšali schopnosti svojho difúzneho modelu, ktorý nazvali EMO. Skratka vychádza z názvu Emote Portrait Alive, čo je ich systém na generovanie portrétnych videí pomocou difúzneho modelu.
| Difúzne modely |
|---|
| Tréning difúznych modelov sa vykonáva tak, že sa do obrázkov pridáva šum, ktorý sa následne učí model odstraňovať. Pri generovaní obrázkov model využíva tento proces obnovy, a vytvára tak realistické obrazy z pôvodného šumu. |
Vedci z inštitútu uvádzajú, že stačí poskytnúť fotografiu a zvukový súbor a EMO následne dokáže generovať AI videá, kde môžu ľudia hovoriť a spievať.
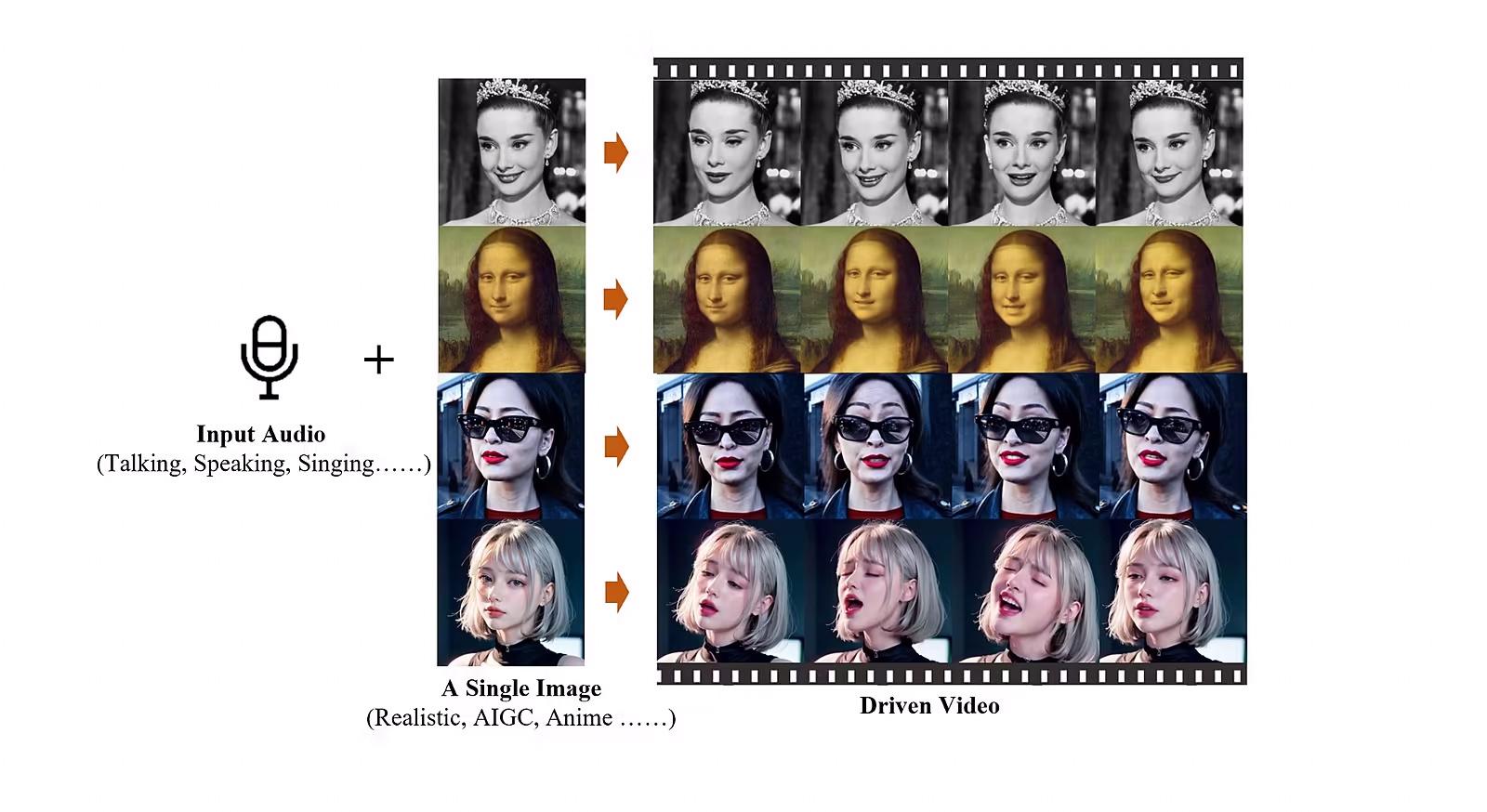
„Naša metóda dokáže generovať hlasové videá s expresívnymi výrazmi tváre a rôznymi polohami hlavy a zároveň dokáže generovať videá s ľubovoľnou dĺžkou trvania v závislosti od dĺžky vstupného videa,“ vysvetľujú autori. Ako je na priloženom videu vidieť, výrazy sú veľmi dôveryhodné.
Celý proces je podľa jeho tvorcov nastavený tak, aby sa v prvej fáze extrahovali rysy z predloženej snímky, a výsledok je potom použitý na vytvorenie série pohyblivých snímok. Druhou je fáza difúzneho procesu, kedy vopred natrénovaný zvukový kodér spracováva zvukové vložky.
Ako to celé prebieha, popisujú tvorcovia v tomto obrázku:
